
LLM-as-Judge for Hallucination Detection: Does the Critic Agent Actually Work?
This is a follow-up to From arXiv to SEC: Building a Multi-Agent Financial Report Analyst with LangGraph. That post ended with: “The remaining question is whether the Critic catches a genuinely hallucinated claim if one slipped through.” This post answers that question.
TL;DR: Built a synthetic evaluation suite to measure the Critic Agent’s hallucination detection accuracy. Tested 70B vs 8B as the judge model. 70B achieved 100% sensitivity (caught all hallucinations) but 67% specificity (flagged 1 clean analysis as insufficient). 8B missed hallucinations and completely failed on borderline cases. The 30% citation threshold works, but model size is the dominant factor in LLM-as-Judge reliability.
1. The Question
finscope’s Critic Agent is the final gate in a 3-agent pipeline. It reviews the Analyzer’s output and checks whether each factual claim is supported by the retrieved source chunks. If more than 30% of claims are uncited, it returns insufficient and triggers a retry (max 2x).
The mechanism was tested for basic functionality — the retry loop fires, the Langfuse trace shows critique: "insufficient" on the first pass. But that only proves the plumbing works. The real question:
If the Analyzer hallucinates a revenue figure or fabricates a risk factor, does the Critic actually catch it?
This is not a trivial question. LLM-as-Judge is known to be lenient — models tend to rate their own outputs favourably. And the Critic is using the same Groq llama-3.3-70b-versatile model that the Analyzer uses. Self-evaluation bias is a real risk.
2. Experimental Design
2.1 Source Data
Pulled 8 real AAPL 10-K chunks from ChromaDB — the same chunks the production pipeline uses. These serve as the ground truth source excerpts that the Critic checks against.
2.2 Synthetic Test Cases
Generated 9 test cases across 3 categories using the same LLM (to simulate realistic output style):
| Type | Count | Description | Expected Verdict |
|---|---|---|---|
| Clean | 3 | Every claim cites a fact from the source chunks | sufficient |
| Hallucinated | 3 | 4 fabricated claims injected (non-existent numbers/facts) | insufficient |
| Borderline | 3 | 10 claims, 3 with numbers altered by 5-15% (~30% threshold) | ambiguous |
The hallucinated cases inject plausible-sounding but completely fabricated claims:
"The company's operating lease vehicles segment has seen a significant
expansion, with 27% of its total revenue coming from this sector."
→ No such figure exists in the source chunks
"Tesla has been investing heavily in research and development, with a
reported expenditure of $1.2 billion in the last quarter alone."
→ Fabricated number, not in any retrieved document
The borderline cases are the interesting ones — they test the 30% threshold boundary. 7 accurate claims + 3 claims with subtly altered numbers (e.g. rounding differently, off by 5-15%). If the Critic is sensitive enough, it should flag these. If it’s too lenient, they’ll pass through.
2.3 Evaluation Pipeline
# Generate test cases
cases = generate_test_cases(chunks) # 9 cases: 3 clean, 3 hallucinated, 3 borderline
# Run each through the Critic
for case in cases:
result = run_critic(context, case["analysis"])
# Compare result["verdict"] against expected
Each test case is evaluated independently — same source context, same Critic prompt, different analysis text. The Critic sees the analysis and source excerpts but has no knowledge of whether the case is clean or hallucinated.
Ran the full suite twice: once with llama-3.3-70b-versatile (70B) and once with llama-3.1-8b-instant (8B) to measure the effect of model size on judge quality.
3. Results
3.1 Confusion Matrix
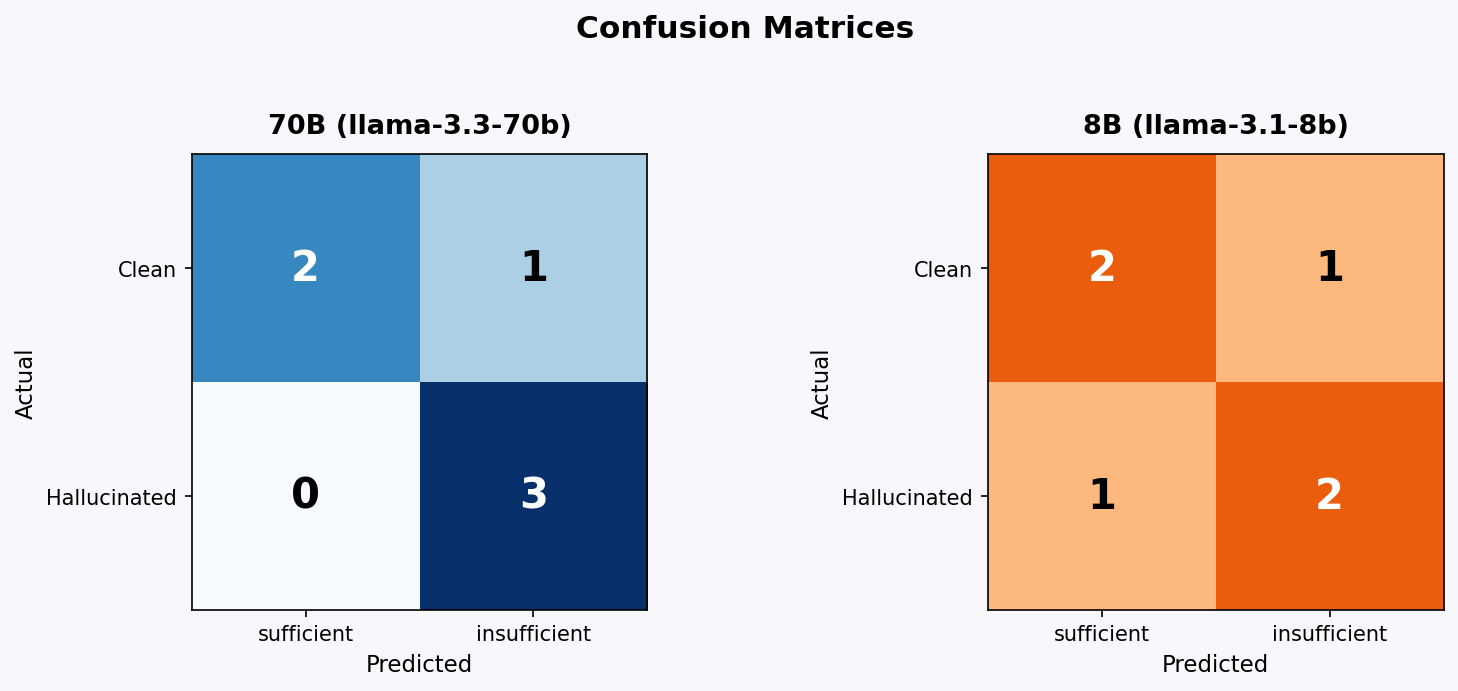
70B (llama-3.3-70b-versatile)
| Predicted sufficient | Predicted insufficient | |
|---|---|---|
| Actual clean | 2 (TN) | 1 (FP) |
| Actual hallucinated | 0 (FN) | 3 (TP) |
8B (llama-3.1-8b-instant)
| Predicted sufficient | Predicted insufficient | |
|---|---|---|
| Actual clean | 2 (TN) | 1 (FP) |
| Actual hallucinated | 1 (FN) | 2 (TP) |
3.2 Summary Metrics
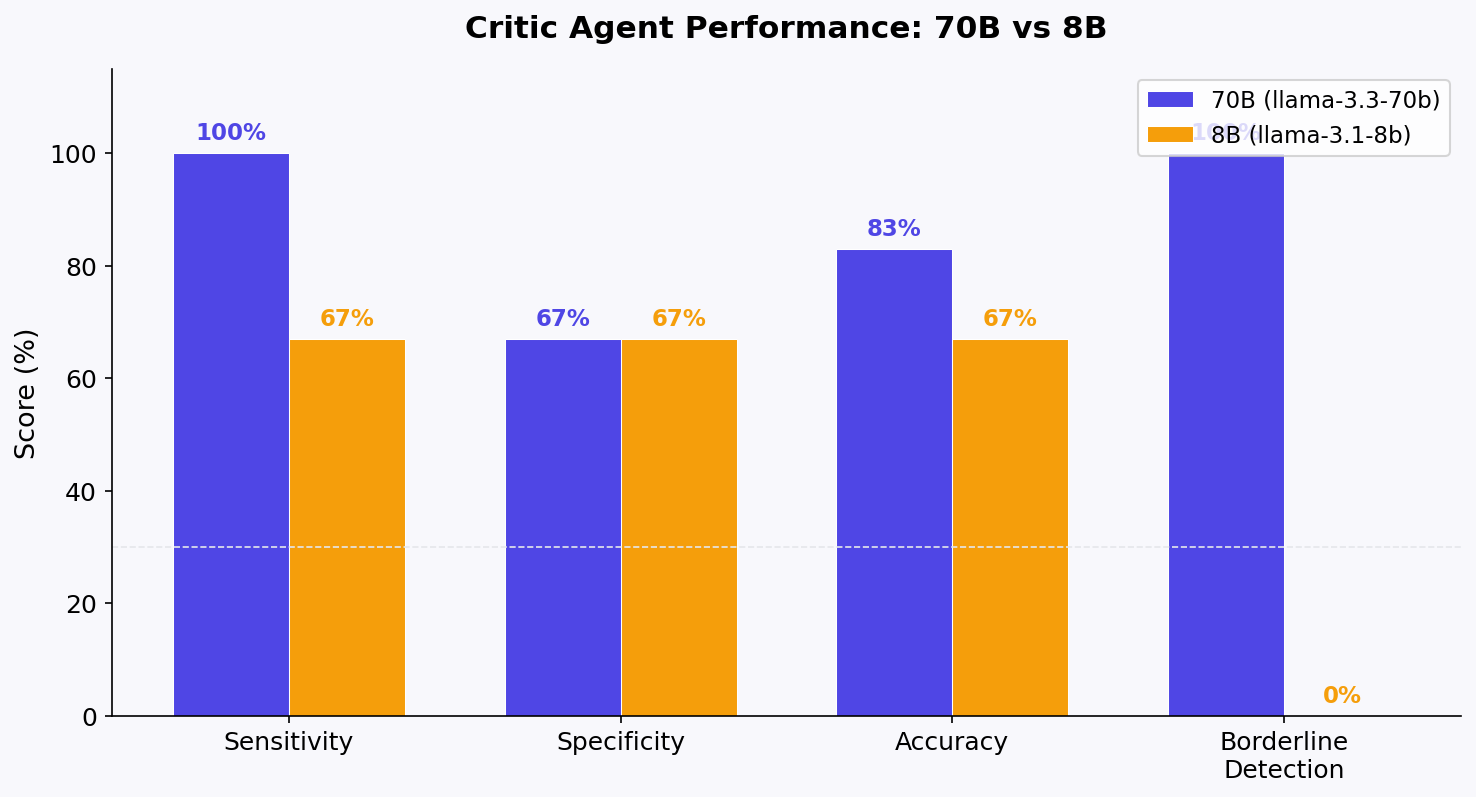
| Metric | 70B | 8B |
|---|---|---|
| Sensitivity (hallucination detection) | 100% (3/3) | 67% (2/3) |
| Specificity (clean pass-through) | 67% (2/3) | 67% (2/3) |
| Accuracy | 83% | 67% |
| Borderline detection | 3/3 caught | 0/3 caught |
3.3 Per-Case Detail (70B)
| Case | Type | Verdict | Cited | Uncited | Correct |
|---|---|---|---|---|---|
| clean_1 | clean | sufficient | 7 | 3 | Y |
| clean_2 | clean | sufficient | 8 | 2 | Y |
| clean_3 | clean | insufficient | 7 | 4 | N (FP) |
| hallucinated_1 | hallucinated | insufficient | 0 | 9 | Y |
| hallucinated_2 | hallucinated | insufficient | 2 | 5 | Y |
| hallucinated_3 | hallucinated | insufficient | 0 | 9 | Y |
| borderline_1 | borderline | insufficient | 6 | 4 | — |
| borderline_2 | borderline | insufficient | 7 | 3 | — |
| borderline_3 | borderline | insufficient | 7 | 3 | — |
3.4 Per-Case Detail (8B)
| Case | Type | Verdict | Cited | Uncited | Correct |
|---|---|---|---|---|---|
| clean_1 | clean | insufficient | 2 | 2 | N (FP) |
| clean_2 | clean | sufficient | 4 | 0 | Y |
| clean_3 | clean | sufficient | 6 | 0 | Y |
| hallucinated_1 | hallucinated | insufficient | 0 | 5 | Y |
| hallucinated_2 | hallucinated | sufficient | 7 | 5 | N (FN) |
| hallucinated_3 | hallucinated | insufficient | 4 | 3 | Y |
| borderline_1 | borderline | sufficient | 7 | 3 | — |
| borderline_2 | borderline | sufficient | 7 | 3 | — |
| borderline_3 | borderline | sufficient | 8 | 2 | — |
3.5 Citation Breakdown
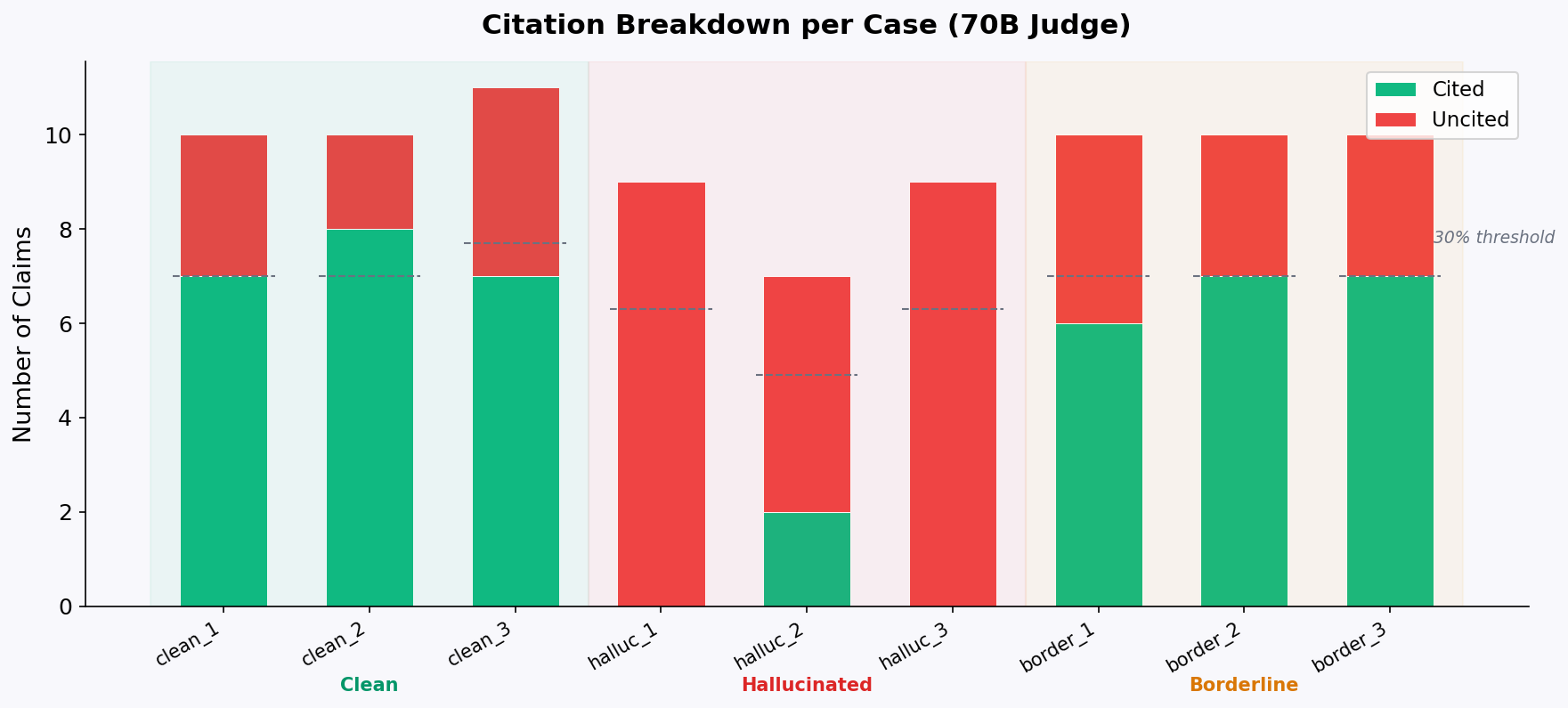
The stacked bar chart shows cited (green) vs uncited (red) claims per case for the 70B judge. The dashed lines mark the 30% threshold — any case where the red portion exceeds the line should be flagged as insufficient. The hallucinated cases are visually obvious (mostly red), while the borderline cases sit right at the threshold boundary.
4. Analysis
4.1 The 70B Critic is Conservative
70B caught every hallucinated case — including hallucinated_2 where 2 of 7 claims happened to align with source text. It correctly identified the 5 uncited claims and returned insufficient.
But it also flagged clean_3 as insufficient (cited=7, uncited=4, ratio=4/11=36%). The analysis was generated from source excerpts only, but the Critic counted paraphrased content as uncited. When the LLM rephrases a source fact rather than quoting it directly, the Critic treats the paraphrase as a new, unsupported claim.
This is a known limitation of LLM-as-Judge: it struggles to distinguish between paraphrase and fabrication. A human reviewer would recognise “the company reported significant revenue” as a paraphrase of a source excerpt mentioning specific revenue figures. The LLM Critic flags it as uncited because the exact wording doesn’t match.
4.2 The 8B Critic Fails at Arithmetic
The 8B model’s most telling failure is hallucinated_2: it counted 7 cited and 5 uncited claims, then returned sufficient. 5/12 = 42% uncited — clearly above the 30% threshold. The model got the counting right but failed the ratio calculation.
This is consistent with known limitations of small language models on arithmetic tasks. The 8B model can identify individual claims as cited or uncited, but cannot reliably compute whether the uncited proportion exceeds the threshold.
4.3 Borderline Detection is the Key Differentiator
This is the most significant finding. The borderline cases had exactly 3 out of 10 claims with subtly altered numbers (5-15% off). Both models reported similar cited/uncited counts (7/3) — but their verdicts diverged completely:
- 70B: All 3 borderline cases →
insufficient. It detected that the altered numbers didn’t match the source excerpts. - 8B: All 3 borderline cases →
sufficient. It failed to notice 5-15% numeric discrepancies.
For a financial analysis system, this is the difference between catching “revenue of $383B” being misreported as “$405B” and letting it through. The 70B model’s numeric precision is materially better.
4.4 The Critic Prompt
The prompt structure matters. The current format forces structured output:
CITED_COUNT: <number>
UNCITED_COUNT: <number>
VERDICT: <sufficient|insufficient>
FEEDBACK: <one sentence>
This makes parsing reliable (_parse_verdict regex extraction), but it also means the verdict depends on the model’s ability to:
- Identify individual claims
- Check each against source text
- Count cited vs uncited
- Compute the ratio
- Apply the 30% threshold
Steps 3-5 are where 8B breaks down. A simpler prompt — “Is this analysis well-supported? Yes/No” — might perform differently, but would lose the granularity needed for debugging.
5. Langfuse Tracing
All experiment runs are traced in Langfuse. The trace structure:
critic-eval-experiment (root, ~297s total)
├── critic-eval-llm-call (test case generation, ×9)
├── critic-eval-judge (evaluation, ×9)
│ └── critic-eval-llm-call (LLM call per judge)
Each observation captures latency per call. The 70B judge calls averaged 17-22s per evaluation, while the 8B calls averaged 9-13s — faster, but the accuracy tradeoff isn’t worth it.
One gap: usageDetails is empty across all observations. Groq’s SDK doesn’t automatically report token usage to Langfuse’s @observe decorator. To get token-level cost tracking, you’d need to either use the OpenAI-compatible wrapper with Langfuse’s OpenAI integration, or manually pass usage data from the Groq response object. For this experiment, latency was sufficient as a proxy.
6. Limitations
Small sample size. n=9 per model (3 per category) is enough to identify directional patterns but not enough for statistical significance. A production evaluation suite should have 30-50+ cases per category.
Self-evaluation bias. The same model family generates the analysis and judges it. The hallucinated cases use obviously fabricated numbers ($1.2B R&D, $500M regulatory credits) that any model would flag. More subtle hallucinations — a correct number attributed to the wrong time period, or a qualitative claim that sounds plausible — would be harder to detect.
Synthetic vs real hallucinations. The test cases are generated by explicitly asking the LLM to fabricate claims. Real-world hallucinations emerge organically and are often more subtle — a confident extrapolation beyond the source data, rather than a clearly fabricated number.
Non-deterministic. temperature=0.3 means the same case may yield different results on re-run. The 70B FP on clean_3 might not reproduce consistently.
7. Conclusion
The Critic Agent works — with caveats:
| Finding | Implication |
|---|---|
| 70B catches all fabricated hallucinations | The mechanism is sound for obvious fabrications |
| 70B catches borderline (5-15%) numeric changes | Useful for financial domain where numbers matter |
| 8B misses hallucinations and all borderline cases | Do not use small models as judges for financial data |
| Both models show 67% specificity | The 30% threshold is slightly too aggressive for paraphrased content |
| The FP comes from paraphrase ≠ citation | Consider raising threshold to 35% or adding a “partially cited” category |
The core takeaway: model size is the dominant factor in LLM-as-Judge reliability. The threshold, the prompt format, the structured output — none of these matter if the judge model can’t do basic arithmetic or detect subtle numeric discrepancies. For finscope’s use case (financial filing analysis where numbers are critical), the 70B model is the minimum viable judge.
What’s Next
- Threshold sweep — generate ROC curves at 20-40% thresholds to find the optimal operating point
- Cross-model evaluation — generate with 8B, judge with 70B (or vice versa) to isolate self-evaluation bias
- Larger sample size — 30+ cases per category for statistical confidence
- Real hallucination injection — instead of fabricated numbers, test with correct numbers from the wrong time period or misattributed claims
Source Code: github.com/choeyunbeom/finscope
Related Post: