
arXiv RAG System: Engineering an Academic Paper Q&A System from Scratch
arXiv RAG System: Engineering an Academic Paper Q&A System from Scratch
Demo
Ask a natural language question → the system retrieves relevant arXiv papers → generates a cited, grounded answer using a local LLM.
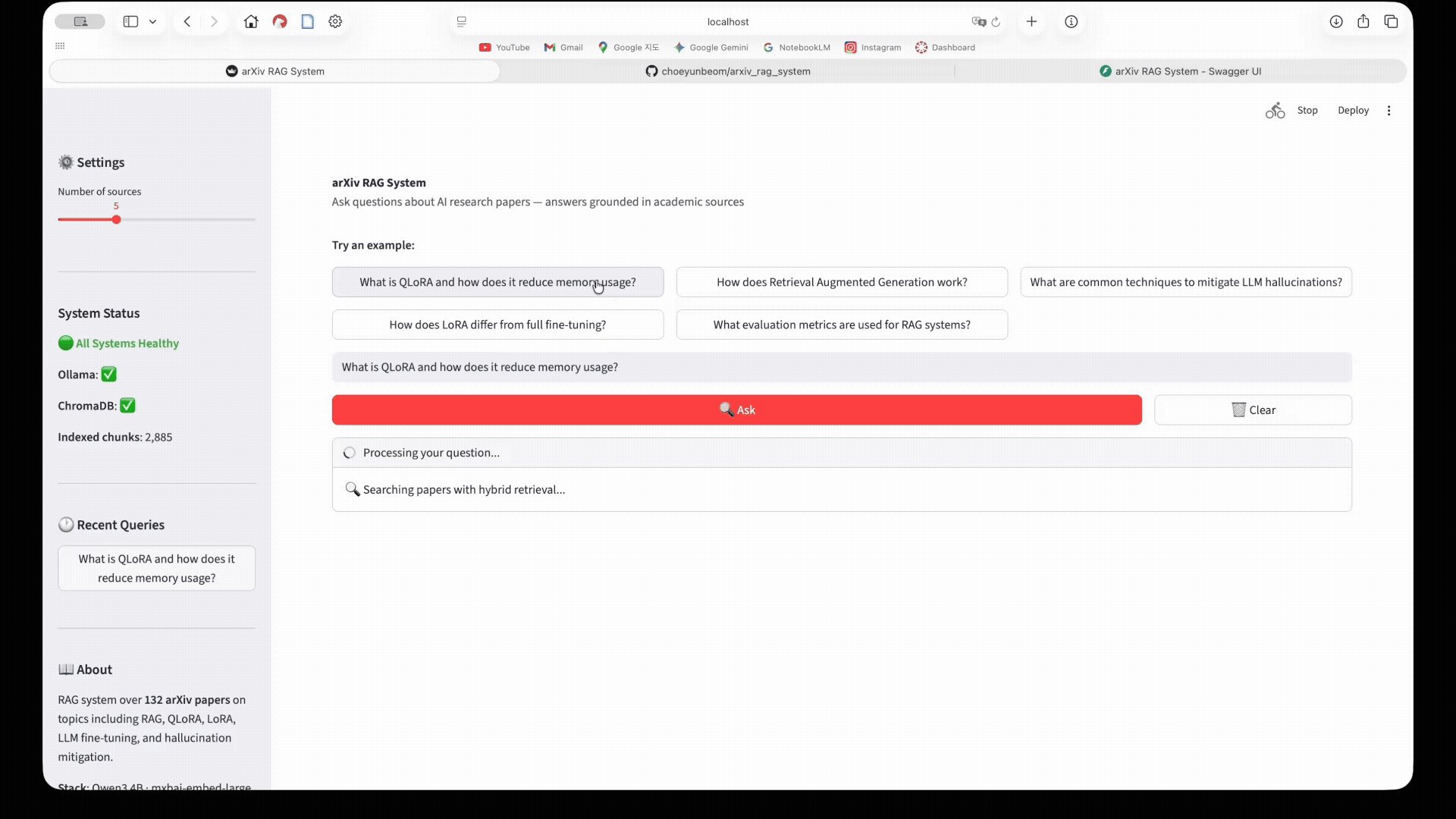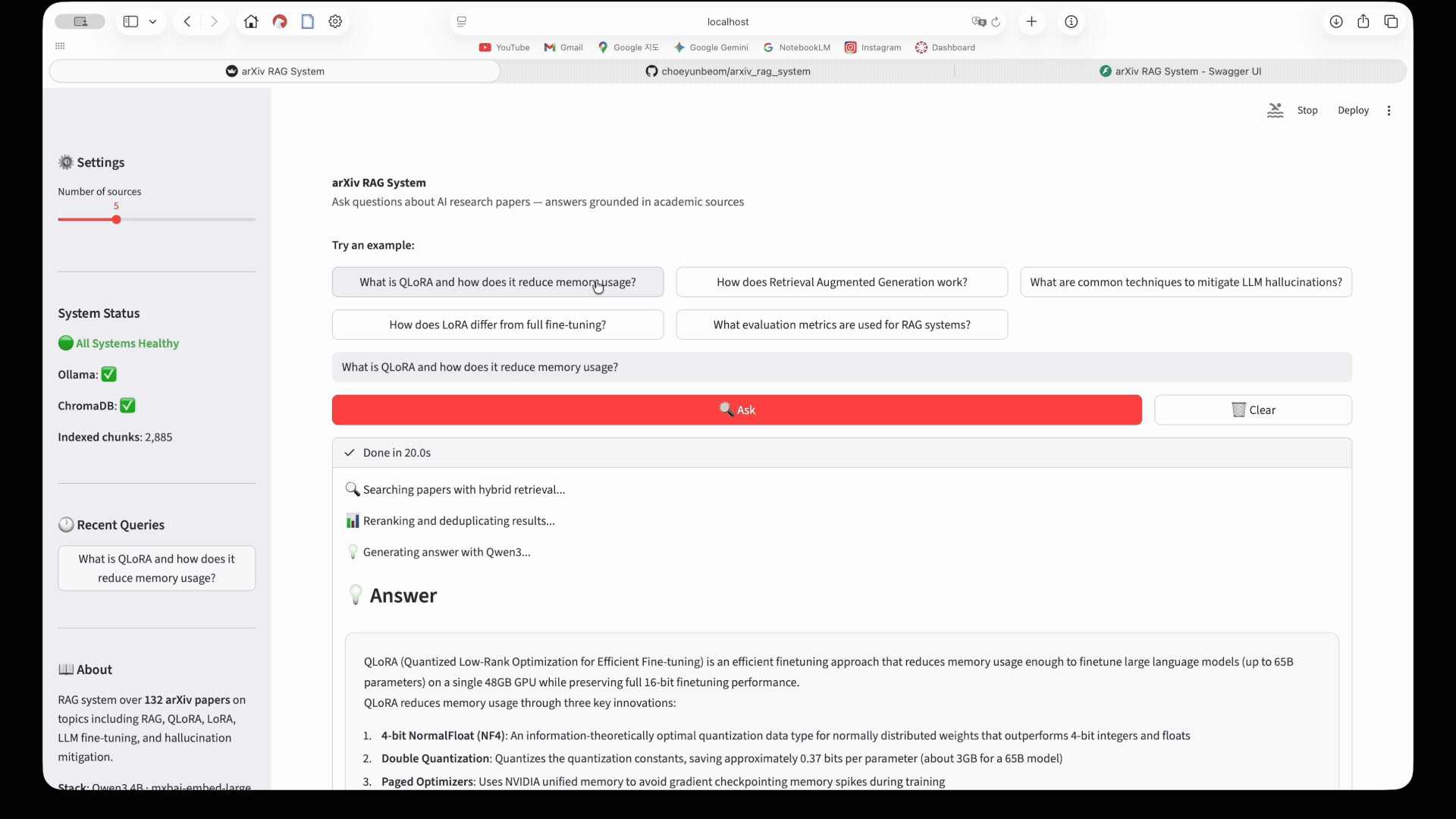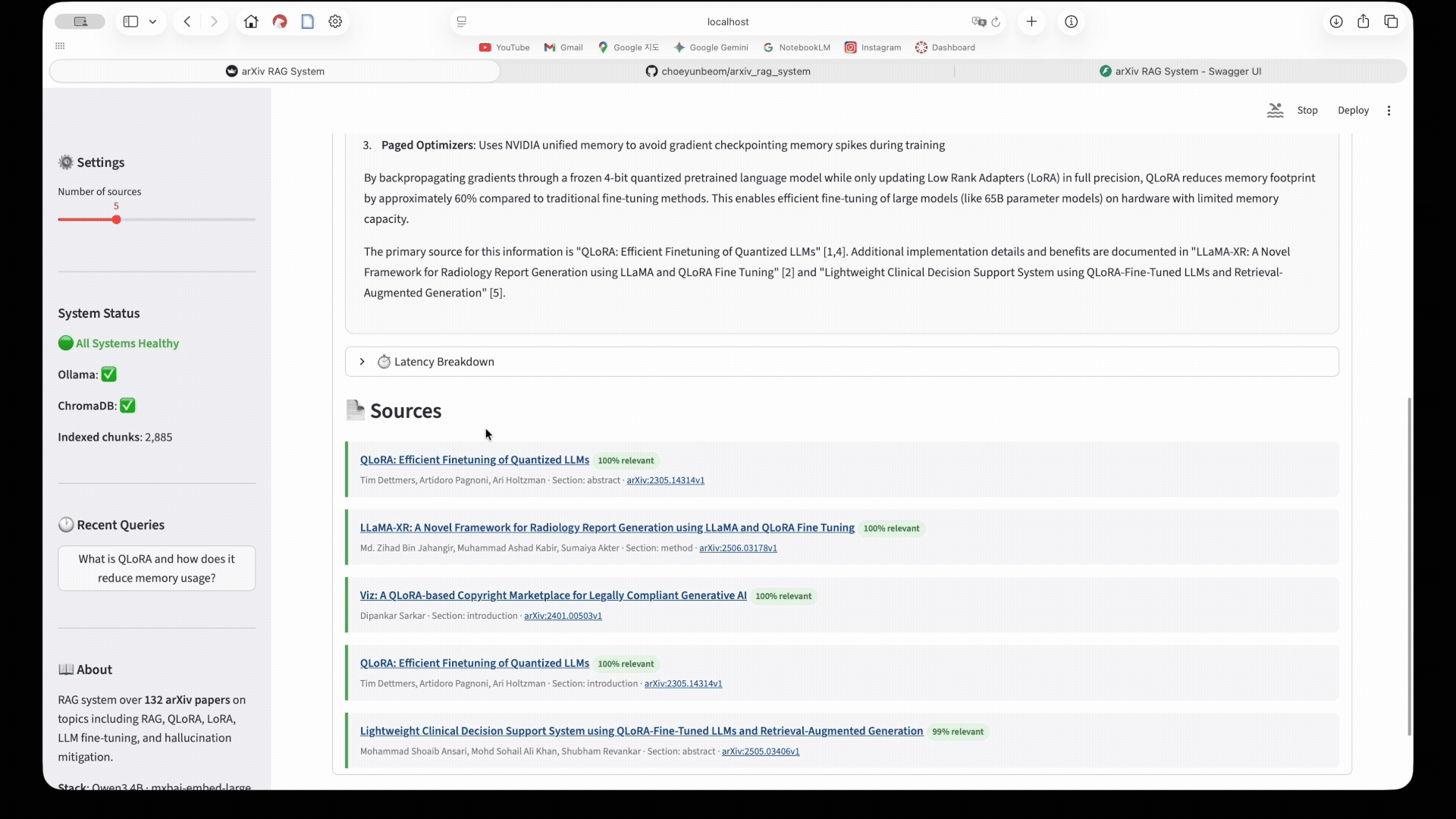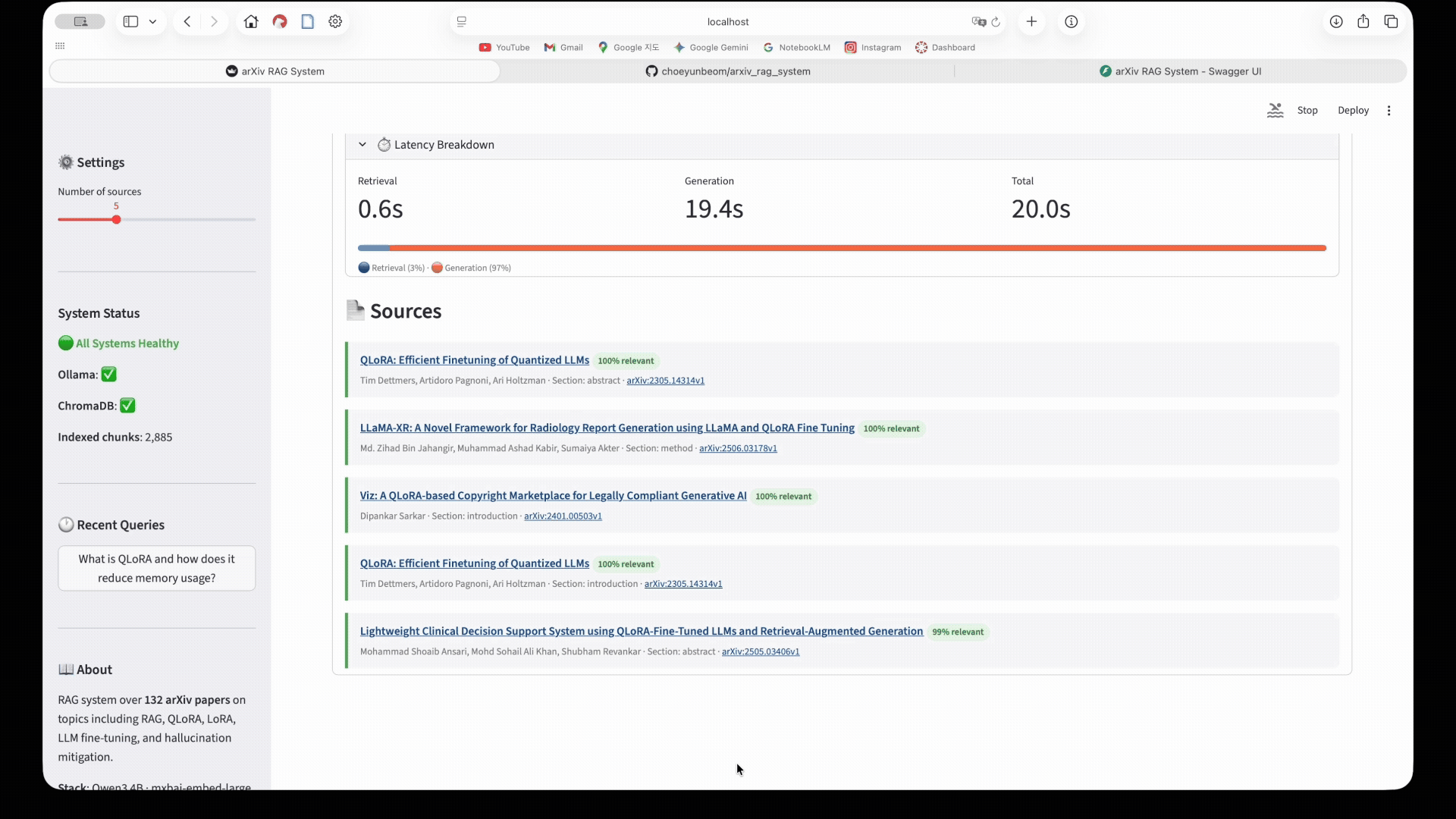
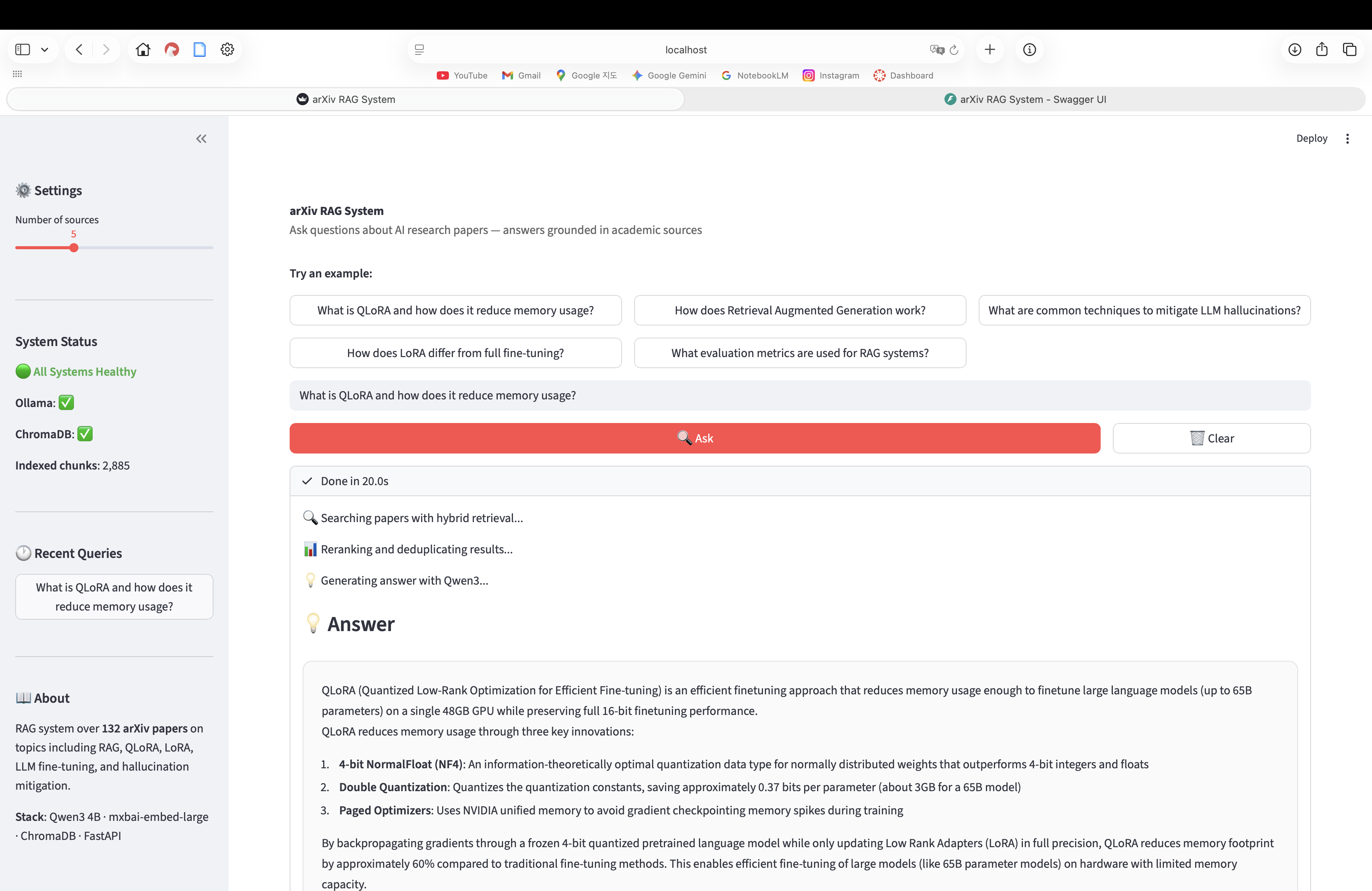
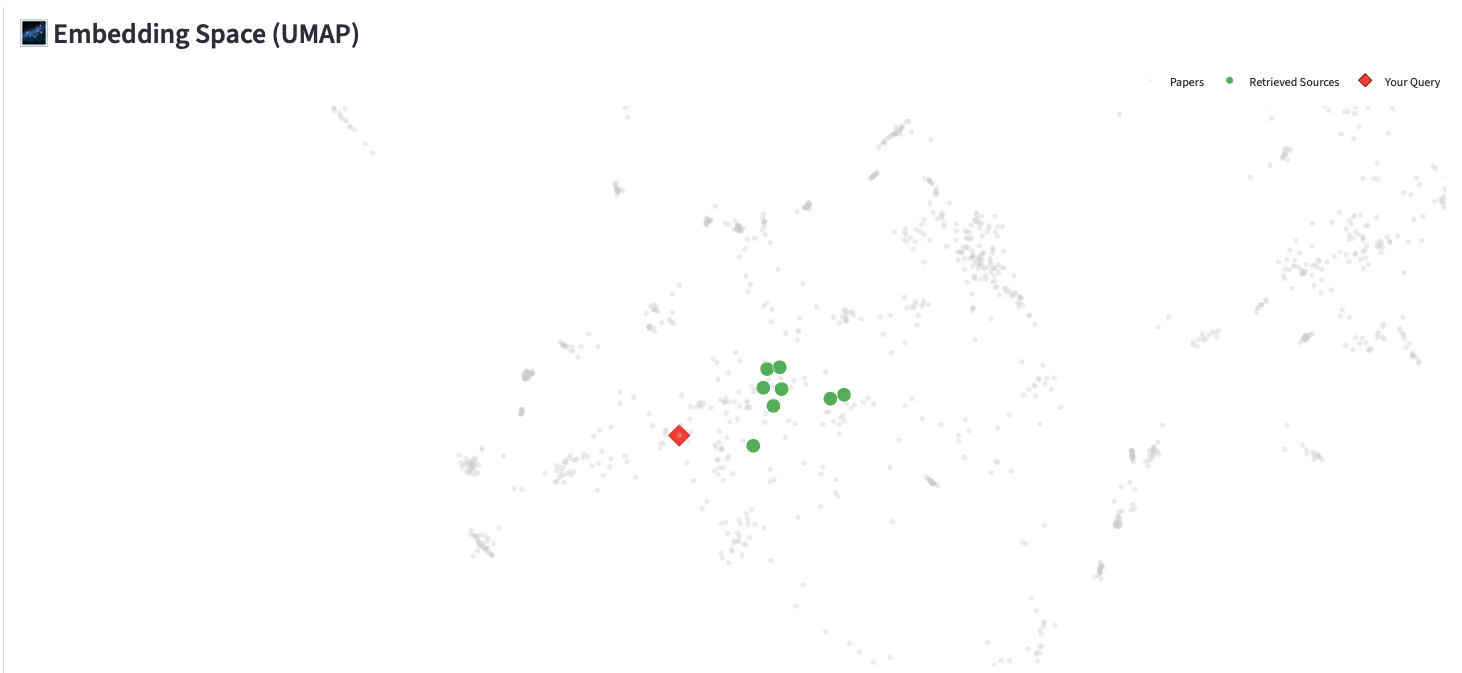
The UI shows the full query flow: enter a question → hybrid retrieval searches 153 arXiv papers → cross-encoder reranks results → Qwen3 4B generates a cited answer. 3D UMAP visualisations map the query to the semantic space of the arXiv corpus. Latency breakdown shows retrieval vs generation time.
TL;DR: Built an end-to-end RAG system for 153 arXiv papers in 7 days. Retrieval went from 60% to 100% hit rate through hybrid search and cross-encoder reranking. LoRA fine-tuning regressed by 28pp due to training data contamination - few-shot prompting won instead.
Abstract
This post documents the 7-day build of an end-to-end Retrieval-Augmented Generation system for querying 153 academic papers from arXiv. Rather than presenting a polished final result, this focuses on the engineering journey: a broken embedding pipeline on Day 1, a systematic retrieval optimisation that hit 100% hit rate, and a fine-tuning experiment that regressed by 28 percentage points due to training data contamination.
Key Contributions:
- Systematic debugging methodology for embedding model failures
- Retrieval optimisation journey: Hit Rate 60% → 100% across 6 experiments
- Quantitative analysis of why LoRA fine-tuning failed a 4B-parameter model
- Evidence-based comparison of zero-shot vs few-shot vs fine-tuned answer generation
1. Introduction
1.1 The Goal
Build a system that can answer questions about recent ML research by grounding answers in actual arXiv papers. The user asks a natural language question; the system retrieves the most relevant chunks from a 153-paper corpus and generates a cited prose answer.
Constraints:
- Fully local: all inference runs on Apple M4 Pro via Ollama, no API calls
- End-to-end: data pipeline, retrieval, generation, evaluation, and deployment included
- Honest evaluation: report regressions and failures alongside successes
1.2 Why This is Hard
RAG systems fail in subtle ways. Bad retrieval produces irrelevant context; the LLM then either hallucinates or generates a correct-sounding answer from the wrong sources. You need to validate every layer independently.
Three layers of challenge in this project:
- Embedding quality: A quantised model may produce a broken vector space
- Retrieval precision: Academic terminology requires both semantic and keyword matching
- Answer generation: Small LLMs are sensitive to prompt format; fine-tuning can hurt more than it helps
2. System Overview
2.1 Final Architecture
graph TD
A["User Query"] --> B["FastAPI Backend\n(POST /query)"]
B --> C["ChromaDB Vector Search (Top-40)\nmxbai-embed-large"]
B --> D["BM25 Keyword Search (Top-40)"]
C & D --> E["RRF Fusion (k=60)"]
E --> F["Cross-Encoder Reranker\nms-marco-MiniLM-L-6-v2"]
F --> G["Section-Aware Deduplication\n(arxiv_id::section key)"]
G --> H["Qwen3 4B (via Ollama)\nSystem prompt + Context"]
H --> I["Cited Answer → Streamlit UI"]
2.2 Final Statistics
Corpus: 153 arXiv papers (RAG, LoRA, hallucination, etc.)
Indexed Chunks: 2,885 (450-token BPE chunks)
Embedding Model: mxbai-embed-large (335M params)
LLM: Qwen3 4B (Q4_K_M via Ollama)
Reranker: ms-marco-MiniLM-L-6-v2 (22M params)
Hit Rate: 100% (15-question benchmark)
MRR: 0.82
Avg Latency: 19s (retrieval: 1.5s, generation: 15-17s)
Tests: 104 (85 unit + 19 integration)
2.3 Tech Stack
| Component | Technology |
|---|---|
| LLM | Qwen3 4B (Ollama, Apple Silicon Metal) |
| Embeddings | mxbai-embed-large (Ollama) |
| Vector Store | ChromaDB (Docker) |
| Sparse Search | rank_bm25 |
| Reranker | cross-encoder/ms-marco-MiniLM-L-6-v2 |
| Backend | FastAPI |
| Frontend | Streamlit |
| Fine-Tuning | LoRA via PEFT + trl (SFTTrainer) |
| CI/CD | GitHub Actions (ruff + pytest) |
| Deployment | Docker Compose |
3. Day 1: The Embedding Model That Broke Everything
3.1 Problem Discovery
After indexing ~4,000 chunks from 153 papers into ChromaDB, I ran a simple test query:
Query: "What is Retrieval Augmented Generation?"
Top results:
[1] dist=0.3472 | A Study about the Knowledge and Use of Requirements Engineering...
[2] dist=0.4033 | Software Engineering for Collective Cyber-Physical...
[3] dist=0.4133 | Morescient GAI for Software Engineering...
The corpus contained dozens of RAG-specific papers. None appeared in the top results. All distances were in the 0.34–0.40 range - suspiciously high when query terms appear verbatim in many documents.
3.2 Debugging Process
Step 1: Confirm chunks exist
# Verified RAG-relevant chunks were present in the index
Found: "Ragas: Automated Evaluation of Retrieval Augmented Generation"
Preview: "We introduce Ragas (Retrieval Augmented Generation Assessment)..."
The data was there. The retrieval was wrong.
Step 2: Direct cosine similarity sanity check
This was the critical test. Rather than trusting ChromaDB’s retrieval, I embedded a query, a known-relevant document, and a known-irrelevant document, then computed cosine similarity directly.
Results with nomic-embed-text (the initial model):
| Pair | Cosine Similarity |
|---|---|
| Query ↔ RAG paper chunk | 0.41 |
| Query ↔ Irrelevant chunk | 0.60 |
The irrelevant document scored higher. The vector space was inverted.
Step 3: Try the recommended fix
nomic-embed-text documentation recommends search_query: and search_document: prefixes:
| Pair | Without Prefix | With Prefix |
|---|---|---|
| Query ↔ RAG paper | 0.41 | 0.54 |
| Query ↔ Irrelevant | 0.60 | 0.69 |
Absolute scores improved, but the ranking remained inverted. The model was fundamentally broken for this use case.
Step 4: Benchmark alternative model
Switched to mxbai-embed-large (335M params):
| Pair | Cosine Similarity |
|---|---|
| Query ↔ RAG paper chunk | 0.76 |
| Query ↔ Irrelevant chunk | 0.49 |
Correct ranking restored immediately.
3.3 Summary
| Model | RAG Similarity | Irrelevant Similarity | Correct Ranking? |
|---|---|---|---|
| nomic-embed-text | 0.41 | 0.60 | No |
| nomic-embed-text + prefix | 0.54 | 0.69 | No |
| mxbai-embed-large | 0.76 | 0.49 | Yes |
After switching and re-indexing, retrieval results were correct:
[1] dist=0.1668 | RAGPart & RAGMask: Retrieval-Stage Defenses Against...
[2] dist=0.1724 | RAG-Gym: Systematic Optimization of Language Agents...
[3] dist=0.1840 | Engineering the RAG Stack: A Comprehensive Review...
[4] dist=0.1853 | MultiHop-RAG: Benchmarking Retrieval-Augmented Gen...
[5] dist=0.1909 | T-RAG: Lessons from the LLM Trenches
3.4 Root Cause
nomic-embed-text is designed to use task-specific prefixes (search_query:, search_document:) that are critical to its retrieval behaviour. Running via Ollama as a GGUF-quantised model, this prefix-conditioned behaviour appears to degrade or break. The Hugging Face version may work correctly; the Ollama-served GGUF variant did not.
Key takeaway: Never trust an embedding model without a basic sanity check. A 3-line cosine similarity test caught a failure that would have made the entire RAG system useless.
4. Day 3: Retrieval Optimisation - 60% to 100% Hit Rate
4.1 Baseline
Starting state after Day 2 (RAG pipeline built, evaluation framework in place):
| Metric | Value |
|---|---|
| Hit Rate | 60.0% |
| MRR | 0.51 |
| Avg Precision | 33.3% |
| Avg Latency | 14.9s |
Configuration: 128-word chunks, dense vector search only, top-5 results.
Target: 80%+ Hit Rate.
4.2 Experiment 1: Chunk Size
Hypothesis: Increasing chunk size reduces context fragmentation, improving coverage of each paper’s ideas.
Finding: Token vs. Word Count Mismatch
Increasing chunk size to 256 words caused batch failures during indexing. Academic text - with LaTeX, markdown table fragments (|Col1|Col2|...), and special characters - produces 2–3× more tokens than expected word count suggests.
Standard English text: ~1.27 tokens/word
Academic text: ~2.27 tokens/word
Ollama returns HTTP 400 for inputs exceeding mxbai-embed-large’s 512-token context window. A 200-word chunk could be 260 tokens or 600+ tokens depending on content.
Solution: Built a fault-tolerant indexer that falls back to individual chunk embedding on batch failure, skipping only the specific chunks that overflow. This is a correctness fix, not an optimisation.
Results:
| Configuration | Hit Rate | MRR | Skipped |
|---|---|---|---|
| 128 words / 64 overlap | 60.0% | 0.51 | ~5 |
| 200 words / 100 overlap | 66.7% | 0.42 | 116 |
MRR decreased slightly - larger chunks from tangentially related papers now ranked higher. This was expected and would be corrected by reranking.
4.3 Experiment 2: Hybrid Search (BM25 + Dense Vector)
Hypothesis: Academic papers contain domain-specific terms (QLoRA, NF4, RAGAS) where exact keyword matching outperforms semantic similarity.
ChromaDB doesn’t support BM25 natively. Solution: a parallel pipeline using rank_bm25 with Reciprocal Rank Fusion (RRF, k=60) to merge vector and BM25 rankings.
RRF fusion implementation (click to expand)
```python def _rrf_fusion(self, vector_ranks: dict, bm25_ranks: dict, k: int = 60) -> list[str]: """Reciprocal Rank Fusion to combine two ranked lists.""" all_ids = set(vector_ranks.keys()) | set(bm25_ranks.keys()) scores = {} for cid in all_ids: score = 0.0 if cid in vector_ranks: score += 1.0 / (k + vector_ranks[cid]) if cid in bm25_ranks: score += 1.0 / (k + bm25_ranks[cid]) scores[cid] = score return sorted(scores.keys(), key=lambda x: scores[x], reverse=True) ```Results:
| Configuration | Hit Rate | MRR | Keyword Coverage |
|---|---|---|---|
| Dense Only (200w) | 66.7% | 0.42 | 66.2% |
| Hybrid (Dense + BM25) | 73.3% | 0.52 | 67.3% |
4.4 Experiment 3: Cross-Encoder Reranking
The idea: A bi-encoder scores query and document independently, then computes similarity. A cross-encoder processes both jointly, attending to their interaction - much more accurate, but too slow to run on the full corpus. Solution: fetch top-40 candidates via hybrid search, then rerank with the cross-encoder to produce final top-5.
Configuration: cross-encoder/ms-marco-MiniLM-L-6-v2 (22M params), deduplication by arxiv_id::section.
Key implementation detail: Without deduplication, the same paper could appear multiple times in the top-5. Section-aware deduplication (arxiv_id::section rather than just arxiv_id) removes redundant chunks while preserving content from different sections of the same paper.
Results:
| Configuration | Hit Rate | MRR | Avg Precision | Latency |
|---|---|---|---|---|
| Hybrid, no reranker | 73.3% | 0.52 | 28.0% | 17.7s |
| Hybrid + Reranker + Dedup | 100% | 0.78 | 40.0% | 19.0s |
+1.3s latency for +26.7%p hit rate. One of the clearest trade-off decisions in the project.
4.5 Experiment 4: Token-Based Chunking
Problem: The 116 skipped chunks from Experiment 1 were a symptom, not the fix. Word-count chunking is fundamentally misaligned with the embedding model’s context window.
Solution: Replace chunk_text() with BPE tokeniser-based splitting using mxbai-embed-large’s actual tokeniser. Chunk size: 450 tokens with 50-token overlap, guaranteeing every chunk fits within the 512-token limit.
Results:
| Metric | Word-based (200w) | Token-based (450t) |
|---|---|---|
| Skipped chunks | 116 | 1 |
| Total indexed | 5,110 | 2,885 |
| Hit Rate | 100% | 100% |
| MRR | 0.78 | 0.82 |
| Keyword Coverage | 69% | 75% |
The reduction in total chunks (5,110 → 2,885) is expected - 450 tokens ≈ 300–350 words, producing fewer but more contextually complete chunks.
Key takeaway: Text splitting in RAG should always use the embedding model’s tokeniser, not word count. This is not a minor optimisation - it is a correctness requirement.
4.6 Complete Optimisation Journey
| Stage | Hit Rate | MRR | Keyword Cov. | Key Change |
|---|---|---|---|---|
| Baseline | 60% | 0.51 | 64% | 128w chunks, dense only |
| + Chunk optimisation | 67% | 0.42 | 66% | 200w chunks, fault-tolerant indexer |
| + BM25 Hybrid Search | 73% | 0.52 | 67% | RRF fusion |
| + Reranker + Dedup | 100% | 0.78 | 69% | Cross-encoder reranking |
| + Token-based chunking | 100% | 0.82 | 75% | BPE tokeniser-based splitting |
| + Section-aware dedup | 100% | 0.82 | 78% | Dedup by arxiv_id::section |
5. Days 4–6: The Fine-Tuning Experiment That Regressed
5.1 What Was Tried
Goal: Fine-tune Qwen3 4B with LoRA to improve three RAG-specific behaviours:
- Answer only from provided context, cite paper titles
- Output clean prose - no markdown headers or bullet points
- Refuse politely when context is insufficient
Training data: 1,997 synthetic Q&A pairs generated from the 153-paper corpus using Qwen3 4B itself via Ollama’s format: json parameter.
| Type | Count | Purpose |
|---|---|---|
| Grounded (60%) | 1,200 | Single-paper context → cited prose answer |
| Synthesis (20%) | 397 | Two-paper context → comparative prose answer |
| Refusal (20%) | 400 | Irrelevant context → polite refusal |
Training configuration:
| Parameter | Value | Rationale |
|---|---|---|
| Base model | Qwen3-4B (bf16) | bf16 for MPS stability |
| LoRA rank (r) | 16 | Balance expressiveness vs parameter count |
| LoRA alpha (α) | 32 | Standard 2× rank ratio |
| Target modules | q/k/v/o_proj, gate/up/down_proj | All attention + MLP projections |
| Epochs | 3 | Monitored via eval loss |
| Effective batch size | 16 (2 × grad_accum 8) | MPS-stable |
| Learning rate | 2e-4 | Standard for LoRA |
| Hardware | Apple M4 Pro, 48GB | MPS backend |
Trainable parameters: 33M / 4,055M (0.81%)
Training results:
| Epoch | Train Loss | Validation Loss |
|---|---|---|
| 1 | 1.1056 | 1.1180 |
| 2 | 1.0227 | 1.0602 ← best |
| 3 | 0.8818 | 1.0640 |
Total training time: 6.8 hours.
5.2 What Happened
3-way evaluation on a 15-question benchmark under identical retrieval conditions:
| Metric | Zero-Shot | Few-Shot | Fine-Tuned |
|---|---|---|---|
| Keyword Coverage | 76.4% | 78.0% | 48.0% |
| BERTScore F1 | 0.786 | 0.805 | 0.683 |
| Source Hit Rate | 100% | 100% | 100% |
| Substantive Rate | 100% | 100% | 100% |
| Avg Word Count | 175 | 177 | 1,614 |
| Avg Latency | 20.0s | 20.8s | 47.7s |
The fine-tuned model scored 28.4 percentage points lower on keyword coverage than zero-shot, with 9× the word count and 2.4× the latency.
BERTScore F1 dropped from 0.805 (few-shot) to 0.683 (fine-tuned) - confirming the regression was real at the semantic level, not just a keyword artifact.
Per-question breakdown (keyword coverage):
| Topic | Zero-Shot | Few-Shot | Fine-Tuned |
|---|---|---|---|
| qlora | 83% | 83% | 83% |
| rag | 100% | 100% | 80% |
| rag_eval | 100% | 100% | 60% |
| vector_db | 83% | 100% | 50% |
| hallucination | 60% | 60% | 20% |
| double_quant | 60% | 60% | 0% |
| ragas (topic) | 100% | 80% | 0% |
5.3 Root Cause: Training Data Contamination
Inspecting the fine-tuned responses revealed the failure mode: every response began by repeating the system prompt instructions verbatim.
Fine-tuned response (actual output):
"Answer in concise prose paragraphs without markdown headers or bullet
points. Do not generalise findings from one paper as universal
recommendations... [continues for ~400 tokens]
QLoRA is a method that reduces memory usage enough to..."
The model parroted the system prompt before answering, inflating word counts to ~1,600 and displacing actual answer content. This caused keyword coverage to collapse to 0% on 6 of 15 questions.
Contamination path:
- Synthetic data generation used Qwen3 with
format: jsonand thinking mode enabled - The model’s
<think>field contained system prompt fragments mixed with reasoning - When parsed as training answers, those fragments were included in training targets
- The model learned that a valid response begins with system prompt text
This is subtle. The data looked correct at a glance - actual answer content was present. The system prompt text preceding it was noise the model learned to treat as signal.
5.4 Why Few-Shot Prompt Engineering Won
The few-shot approach added ~350 tokens of examples covering the same three behaviours - grounded answering, multi-paper synthesis, and refusal:
Few-shot overhead: ~350 tokens
Latency increase: +0.8s
Keyword coverage gain: +1.6%p vs zero-shot
For a 4B-parameter model: few-shot prompt engineering outperformed 6.8 hours of LoRA fine-tuning on every metric.
5.5 What I Would Do Differently
- Validate training data for instruction leakage - automated checks rejecting any training answer containing system prompt fragments
- Use a separate model for data generation - generating data with the same model that will be fine-tuned, with thinking mode enabled, creates contamination risk
- Establish the few-shot baseline first - fine-tune only if there is a measurable gap that prompt engineering cannot close
- Use a larger base model (7B+) - at 4B parameters, LoRA fine-tuning on 2K examples shifts style while eroding topic coverage
- Quantise both models identically - base used Q4_K_M, fine-tuned used Q8_0; this introduces a confounding variable in evaluation
6. Production Infrastructure
6.1 Testing (104 tests)
All external dependencies mocked at module level. Full test suite runs in 0.82 seconds with zero network requirements.
| Module | Tests | Coverage |
|---|---|---|
chunker |
33 | Reference stripping, citation detection, text cleaning, quality filter, token splitting |
llm_client |
16 | <think> tag cleaning, payload construction, temperature, endpoint handling |
rag_chain |
17 | Prompt DI, context formatting, source deduplication, full pipeline |
hybrid_retriever |
19 | RRF fusion, tokenizer, deduplication, sigmoid normalisation |
19 integration tests cover the full HTTP cycle through FastAPI’s TestClient:
POST /query: successful queries, validation errors, Ollama unavailable (503), timeout (504)GET /health: all healthy, Ollama down, ChromaDB down, both down- Response schema validation throughout
6.2 CI/CD
GitHub Actions runs ruff lint + pytest on every push and pull request. Configured in .github/workflows/ci.yml:
jobs:
lint:
- run: ruff check src/ tests/
test:
- run: pytest tests/ -v
First PR (feat/ci-cd) passed CI automatically.
6.3 Deployment
Docker Compose deploys three services:
| Service | Image | Port | Notes |
|---|---|---|---|
| chromadb | chromadb/chroma:latest | 8200 | Persistent volume |
| api | Dockerfile.api | 8000 | FastAPI + reranker |
| ui | Dockerfile.ui | 8501 | Streamlit frontend |
Ollama runs on the host (required for Apple Silicon Metal GPU), reached from containers via host.docker.internal:11434.
Key detail: depends_on uses condition: service_healthy so containers wait for dependencies to be genuinely ready, not just started.
6.4 Latency Profiling
Adding timing instrumentation to the RAG chain revealed the actual bottleneck:
Retrieval breakdown:
ChromaDB vector search: ~0.3s
BM25 keyword search: ~0.1s
Cross-encoder reranker: ~1.1s
Total retrieval: ~1.5s
Generation: ~15-20s
Any retrieval optimisation that doesn’t address LLM serving infrastructure will have limited impact on end-to-end latency. The reranker’s 1.1s is already the dominant retrieval cost.
7. Development Timeline
| Day | Focus | Key Outcomes |
|---|---|---|
| 1 | Infrastructure | 153 papers crawled, parsed, chunked, indexed. Caught embedding model failure via cosine similarity test. |
| 2 | RAG Pipeline | FastAPI + Streamlit serving. Evaluation pipeline with 15-question benchmark. Qwen3 thinking mode fix. |
| 3 | Retrieval Optimisation | Hit Rate 60% → 100%, MRR 0.51 → 0.82. Hybrid search + cross-encoder reranking. |
| 4 | Fine-Tuning Prep | 1,997 synthetic Q&A pairs generated. Code quality refactoring. |
| 5 | Fine-Tuning & Eval | LoRA training, GGUF conversion, Ollama deployment. Evaluation showing regression. |
| 6 | Testing & CI/CD | 104 tests (unit + integration). GitHub Actions. Docker Compose. Few-shot baseline revealing fine-tuning root cause. |
| 7 | UI & Demo | Streamlit improvements (error handling, latency viz). API docs. BERTScore evaluation. |
8. Lessons Learned
8.1 Embedding Models
Lesson: Quantisation can break task-specific behaviour.
A model trained to use prefix conditioning for retrieval may lose that capability in GGUF format. The sanity check is mandatory:
# Three lines that saved the entire project
sim_relevant = cosine_similarity(query_embed, relevant_embed)
sim_irrelevant = cosine_similarity(query_embed, irrelevant_embed)
assert sim_relevant > sim_irrelevant, "Vector space is inverted"
8.2 Chunking
Lesson: Word-count chunking is a correctness bug for academic text.
Academic text tokenises at 2.27× the word rate of standard English. Always use the embedding model’s actual tokeniser. The 116-chunk skip count was the symptom; switching to BPE splitting eliminated it.
8.3 Hybrid Retrieval
Lesson: Neither semantic nor keyword search alone is sufficient for academic text.
Domain-specific terminology (model names, acronyms, paper titles) requires exact matching. Semantic search alone misses keyword-heavy queries; BM25 alone misses paraphrase queries. RRF fusion captures both.
8.4 Fine-Tuning Small Models
Lesson: Training data contamination is easy to miss and catastrophic.
Automated checks for instruction leakage in synthetic data are essential, not optional. For 4B-parameter models, few-shot prompting often achieves the same goals with a fraction of the cost and risk.
The pattern: If the training data generator uses thinking mode or chain-of-thought, validate that reasoning artifacts are not leaking into the training targets.
8.5 Evaluation
Lesson: BERTScore and keyword coverage together are much more informative than either alone.
A model can retain semantic understanding while failing on keyword coverage (or vice versa). Running both surfaces which failure mode is actually present. In our case, BERTScore confirmed the fine-tuning regression was real, not a keyword matching artifact.
9. Limitations & Future Work
Current Limitations
- In-memory BM25: All chunks loaded into memory. Sufficient for 153 papers (~3K chunks). For larger corpora, would need ElasticSearch/OpenSearch.
- Synchronous Ollama calls: Adequate for single-user demo. Multi-user serving would need
httpx.AsyncClient. - Ollama not containerised: Runs on host for Apple Silicon Metal GPU access. Cloud deployment would need a GPU-enabled container or API-based LLM.
- Evaluation dataset: 15 Q&A pairs is sufficient for directional comparison but not for statistical significance claims.
Next Steps
- Domain-specific reranker:
ms-marco-MiniLM-L-6-v2is trained on web search data. A SciBERT-based or BGE-Reranker may perform better on academic text with mathematical notation. - Fine-tuning (revisited): Re-run with contamination-free training data generated by a separate model, with automated instruction leakage checks.
- Larger corpus: The 153-paper corpus was chosen for tractability. Scaling to 1,000+ papers would test the in-memory BM25 limitation.
- Streaming: The 15–20s generation latency is visible to users. Adding streaming to the Streamlit UI would improve perceived performance without changing actual latency.
10. Conclusion
Starting from zero, across 7 days:
- Caught and fixed a broken embedding model through a 3-line sanity check on Day 1
- Improved retrieval from 60% to 100% hit rate through 6 systematic experiments
- Identified training data contamination as the cause of a 6.8-hour fine-tuning failure
- Demonstrated that few-shot prompting outperformed LoRA fine-tuning for a 4B-parameter model on this task
- Shipped an end-to-end deployed system with 104 tests, CI/CD, and Docker Compose deployment
More importantly, the debugging methodology is transferable:
1. Isolate each layer independently (embedding, retrieval, generation)
2. Run quantitative sanity checks before building on any component
3. Log everything - failure modes are discovered in the data, not by intuition
4. Establish baselines before investing in complex approaches (few-shot before fine-tuning)
5. Report regressions honestly - they teach more than successes
Source Code: github.com/choeyunbeom/arxiv_rag_system
Detailed Logs: