
DefectVision: Building a Real-Time Manufacturing Defect Detector Trained on Normal Images Only
DefectVision: Building a Real-Time Manufacturing Defect Detector Trained on Normal Images Only
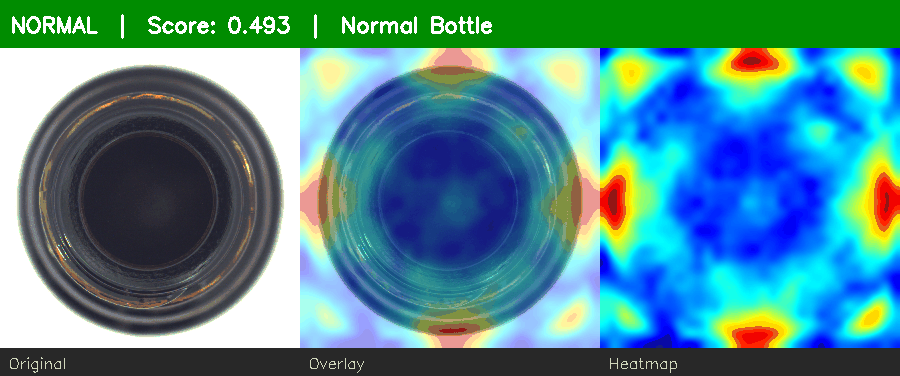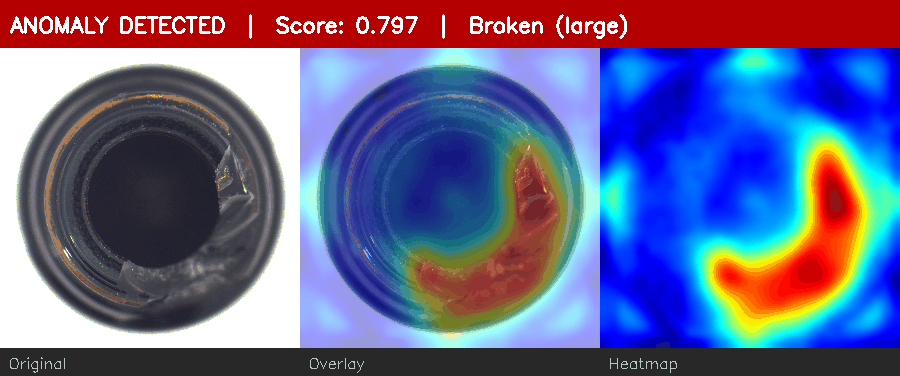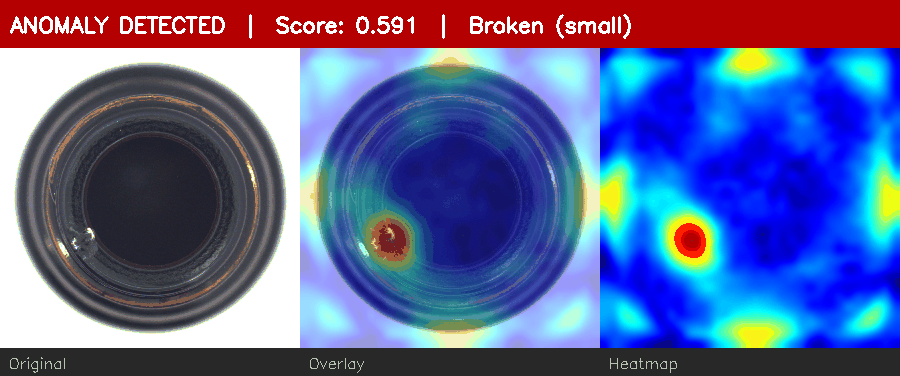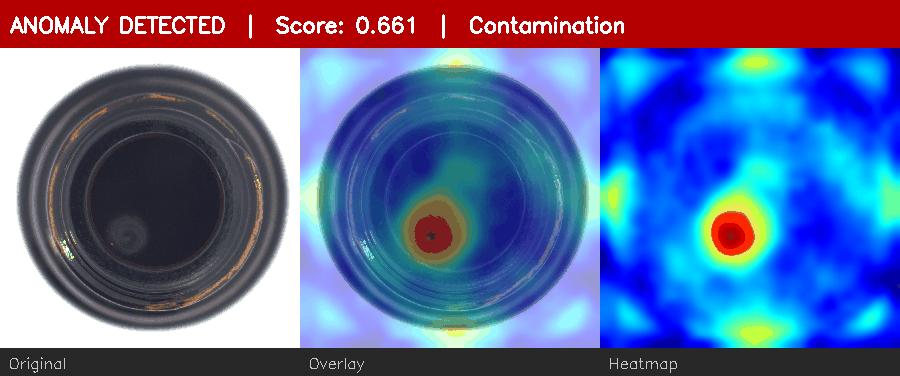 Normal bottle → low score. Defective bottle → red heatmap + ANOMALY alert.
Normal bottle → low score. Defective bottle → red heatmap + ANOMALY alert.
TL;DR: Built a real-time manufacturing defect detection system using PatchCore (unsupervised anomaly detection) — trained on normal images only, no labeled defects required. Hit 100% Image AUROC on MVTec AD bottle, then watched it drop 8–20pp on the harder MVTec AD 2 benchmark. Tried lighting augmentation to close the gap — it made things worse, for reasons specific to how memory-bank methods work. Shipped as a FastAPI + Streamlit pipeline with webcam streaming and a /calibrate endpoint for on-site threshold tuning.
Abstract
This post documents the build of a real-time manufacturing defect detection system using unsupervised anomaly detection. The core constraint — no labeled defect data — led to PatchCore, a memory-bank method that learns normality from good samples only. The system achieved 100% Image AUROC on MVTec AD 1, then dropped 8–20pp on the harder MVTec AD 2 benchmark under multi-lighting conditions. The counterintuitive finding: lighting augmentation made performance worse, because PatchCore’s frozen backbone means augmentation widens the normal distribution in feature space rather than improving robustness. Shipped as a FastAPI inference API with OpenVINO export, threaded webcam streaming, and a /calibrate endpoint for on-site threshold tuning.
Key Contributions:
- Systematic model comparison (PatchCore vs PaDiM vs EfficientAD) with quantitative justification
- Cross-benchmark evaluation exposing the gap between MVTec AD 1 and AD 2
- Analysis of why augmentation hurts memory-bank methods (frozen backbone + distribution widening)
- Production inference pipeline with OpenVINO export, threaded capture, and runtime calibration
- 14/14 tests with CI pipeline (ruff + pytest + Docker build)
1. Why This Project
My previous projects — arXiv RAG, FinScope — were all NLP. The TORCS racing agent used sensor data but not vision. I wanted to build something end-to-end in CV: raw pixels in, real-time decision out.
Manufacturing defect detection was the right scope. It is a real industrial problem where the constraint — you only have normal samples, never enough defect data — forces you to use unsupervised methods rather than defaulting to a supervised classifier. That constraint is what makes the problem interesting and the solution practical.
2. Why Unsupervised?
In real factories, defects are rare and unpredictable. A supervised model (YOLO, image classification) needs hundreds of labeled defect images per defect type — and every time a new defect appears, you relabel and retrain.
PatchCore flips this: train on normal samples only. The model learns “what normal looks like” and flags any deviation — including defect types it has never seen. Training on a new product requires ~100–200 normal images. No labeling. No anticipating defect categories in advance.
3. Architecture
graph TD
A["Webcam / RTSP"] --> B["Camera\n(OpenCV threaded capture)"]
B -->|"frame (BGR)"| C["FrameProcessor"]
C -->|"POST /predict"| D["FastAPI Inference API"]
D --> E["PatchCorePredictor\n(PyTorch or OpenVINO)"]
E -->|"anomaly score\nheatmap\noverlay"| D
D -->|"overlay (base64 PNG)"| C
C --> F["Streamlit Dashboard"]
F --- G["Live feed + heatmap overlay\nScore time-series chart\nNORMAL / ANOMALY status"]
The system has four layers: training (offline), inference API (FastAPI), video streaming (OpenCV with threaded capture), and dashboard (Streamlit). Each layer is independently testable. The API returns base64-encoded heatmap overlays — the dashboard and stream client are both thin consumers.
4. Model Selection: PatchCore vs PaDiM vs EfficientAD
All three models were benchmarked on MVTec AD bottle under identical conditions.
| Model | Image AUROC | Pixel AUROC | Train Time |
|---|---|---|---|
| PatchCore | 1.0000 | 0.9816 | 211s |
| PaDiM | 0.9913 | 0.9809 | 47s |
| EfficientAD | excluded | excluded | 1+ hr |
PaDiM is 4.5x faster to train but ~1% lower on accuracy. For a one-time training cost, accuracy wins.
Why EfficientAD was excluded: it requires an additional 1.56 GB ImageNette dataset as negative examples, enforces train_batch_size=1, and defaults to max_epochs=1000 — making training take over an hour per category. The external data dependency alone makes it impractical for rapid retraining on new product types, which is the core requirement for manufacturing deployment.
5. MVTec AD Results — Then Reality Hit with AD 2
MVTec AD (the standard benchmark)
| Category | Image AUROC | Pixel AUROC |
|---|---|---|
| bottle | 1.0000 | 0.9815 |
| screw | 0.9820 | 0.9894 |
| capsule | 0.9781 | 0.9877 |
All three exceed target thresholds. PatchCore on MVTec AD 1 is a solved problem.
MVTec AD 2 (2025 — the harder benchmark)
| Category | Image AUROC | Pixel AUROC |
|---|---|---|
| vial | 0.9245 | 0.9396 |
| fruit_jelly | 0.8000 | 0.9552 |
8–20 percentage point drop on Image AUROC. Same model, same config. The difference is the dataset.
Why AD 2 is harder:
- Multi-lighting conditions — AD 2 test images include regular, overexposed, and shift-1/2/3 illumination variants. The model trained on a single lighting condition can’t distinguish lighting-induced appearance changes from actual defects.
- Transparent and overlapping objects — vials and fruit jelly have complex refraction and occlusion patterns. AD 1 objects (bottles, screws, capsules) have opaque surfaces with predictable textures.
- High intra-class normal variance — AD 2 normal samples exhibit more variation (different fill levels, positional shifts), compressing the gap between normal and anomalous patch distances.
Pixel AUROC is more resilient (0.92–0.96) because spatial localisation depends on relative patch distances rather than absolute thresholding — less sensitive to global illumination shifts. This aligns with published SOTA: methods scoring >90% AU-PRO on AD 1 typically drop below 60% on AD 2.
The takeaway: benchmark performance is not production performance. AD 2 is closer to what a real factory looks like.
Attempted Mitigation: Lighting Augmentation
The obvious fix for a lighting-induced performance drop is to augment training data with lighting and geometry transforms. Tested on vial:
| Config | Augmentation | Image AUROC | Pixel AUROC |
|---|---|---|---|
| baseline | none | 0.9245 | 0.9396 |
| lighting | ColorJitter + RandomAutocontrast | 0.8679 | 0.9235 |
| geometry | HFlip + Rotation | 0.7495 | 0.9363 |
Augmentation consistently degrades performance.
This was counterintuitive until I thought about how PatchCore works. The backbone (WideResNet50) is frozen — never trained. Augmented training images produce feature vectors representing “normal images under varied conditions”, which bloats the memory bank with a wider distribution of normal features. This compresses the distance gap between normal and anomalous patches at test time, making anomalies harder to detect.
This is a fundamental property of memory-bank methods: augmentation that helps discriminative models (by improving generalisation) actively hurts PatchCore by widening the normal distribution in feature space.
The correct mitigation is not augmentation but collecting training images that cover the actual lighting conditions seen at test time. A model trained under the same multi-lighting setup as the test set would eliminate the distribution shift entirely — the problem is data coverage, not model robustness.
6. The Inference API
Core Prediction
PatchCorePredictor supports two runtimes — PyTorch (for development on Apple Silicon) and OpenVINO (for Intel edge deployment):
# PyTorch path: loads .ckpt, uses torchvision v2 transforms
# OpenVINO path: loads .xml IR, manual numpy preprocessing
# (resize + ImageNet normalise + NCHW transpose)
The threshold is read from checkpoint metadata (model.image_threshold.value) and can be overridden via environment variable or the /calibrate endpoint.
/calibrate — On-Site Threshold Tuning
The checkpoint threshold is trained on MVTec AD images. Real-world images from a factory webcam have different lighting, backgrounds, and camera angles. A static threshold produces false positives.
curl -X POST http://localhost:8000/calibrate \
-F "files=@normal1.jpg" -F "files=@normal2.jpg" \
-F "files=@normal3.jpg"
{
"new_threshold": 0.62,
"mean_score": 0.35,
"std_score": 0.09,
"n_images": 3
}
The endpoint accepts N normal images, runs prediction on each, and computes threshold = mean + k * std (default k=3.0). The calibrated threshold is saved to calibration.json and persists across server restarts — loaded with priority: env THRESHOLD > calibration.json > checkpoint default.
Bug caught during code review: the original /calibrate was computing the threshold from normalised scores (0–1 range) while /predict compared against the raw score threshold. Calibration in normalised space, detection in raw space — the calibrated threshold was meaningless. Fixed by using raw_score consistently.
7. Real-Time Streaming Pipeline
Threaded Camera Capture
Camera runs a background thread that reads frames continuously from OpenCV. The main thread calls read() and gets the latest frame immediately — no blocking on camera I/O.
Non-Blocking Inference
The naive approach — call /predict on every frame at 30 FPS — saturates the API (each prediction takes ~50ms). FrameProcessor uses a queue-based architecture:
_infer_queue(maxsize=1): camera thread enqueues frames withput_nowait, dropping if the worker is busy_result_queue(maxsize=1): worker thread returns results- Last overlay is cached and reused on non-inference frames — no visual flicker
Default: inference every 5 frames (~6 inferences/sec at 30 FPS).
Exponential Backoff
When the API is unreachable, the processor backs off (1s → 2s → 4s → … → 30s max) and resets on success. Without this, a down API produces thousands of error log lines per second.
Graceful Shutdown
The original _inference_worker used time.sleep(self._backoff) for backoff. At max backoff (30s), calling close() blocked for up to 30 seconds. Replaced with self._stop_event.wait(timeout=self._backoff) — close() sets the event, waking the worker immediately.
8. OpenVINO Export
The model exports to OpenVINO IR for Intel edge deployment. No speedup on Apple M4 (0.97x — OpenVINO falls back to generic CPU while PyTorch uses MPS). The expected 2–5x gain would materialise on Intel hardware (NUCs, industrial PCs).
One export issue worth noting: Anomalib’s engine.export() failed because torch.export cannot handle torchvision v2 transforms bundled into the model. Workaround: export model.model (the underlying PatchcoreModel) directly via torch.onnx.export(), then convert ONNX → OpenVINO IR with openvino.convert_model(). Preprocessing handled separately at inference time.
9. Dependency Hell
Three conflicts surfaced during setup:
- numpy 2.x broke imgaug —
np.sctypeswas removed in NumPy 2.0. Anomalib depends on imgaug, which usesnp.sctypes. Pinned tonumpy==1.26.4. - ollama SDK broke Anomalib — Anomalib’s VlmAd backend uses
_encode_image, a private API that changed in newer ollama versions. Pinned toollama==0.3.3. - matplotlib API change —
tostring_rgbwas renamed totostring_argbin newer matplotlib, and the return format changed from 3-channel to 4-channel. Patched the Anomalib source.
These are the kinds of issues that don’t appear in any tutorial. Anomalib 1.2 was released before NumPy 2.0, before the ollama SDK restructure, and before the matplotlib ARGB change. Pinning versions solved it, but finding the right pins took longer than the actual training.
10. Tests
14 tests across inference and stream modules:
| File | Tests |
|---|---|
test_inference.py |
Health endpoint, predict schema, invalid file → 422, mock predictor, /calibrate threshold update, /calibrate empty → 422, /calibrate k parameter, model load + score ordering |
test_stream.py |
Overlay shape, cache reuse, no result before first inference, API error fallback, anomaly label |
Model-dependent tests auto-skip in CI via @pytest.mark.skipif(not MODEL_AVAILABLE, ...). The CI pipeline runs ruff lint + pytest + Docker build smoke test.
Test mock lesson: patch.object(main_module, "_predictor", fake) doesn’t override the value assigned by the lifespan handler during TestClient startup. The lifespan creates a new PatchCorePredictor on startup, ignoring the patched module attribute. Fixed by also patching PatchCorePredictor.__init__ so the lifespan assigns the mock.
11. Results Summary
| Metric | Value |
|---|---|
| Image AUROC (AD 1, bottle) | 1.0000 |
| Image AUROC (AD 2, vial) | 0.9245 |
| Image AUROC (AD 2, fruit_jelly) | 0.8000 |
| Inference latency (PyTorch, M4) | 47.7ms |
| Tests | 14/14 passing |
| Training time (bottle) | 211s |
| Training data required | Normal images only |
The 8–20pp drop from AD 1 to AD 2 is the most important number in this project. It quantifies the gap between benchmark performance and something closer to production reality. Lighting augmentation — the obvious mitigation — made things worse because PatchCore’s frozen backbone means augmentation widens the normal distribution rather than improving robustness. The correct fix is data coverage, not data augmentation.
12. Lessons Learned
-
Benchmark performance is not production performance. 100% AUROC on MVTec AD 1 dropped to 80% on AD 2. The difference is entirely environmental — multi-lighting, transparent objects, higher intra-class variance. Any claim about model accuracy needs to specify which benchmark, under which conditions.
-
Augmentation is not universally helpful. For discriminative models (CNNs, transformers), augmentation improves generalisation. For memory-bank methods like PatchCore, it widens the normal distribution in feature space and compresses the gap between normal and anomalous patches. The intervention that helps most supervised methods actively hurts this class of unsupervised methods.
-
Calibration belongs at deployment, not at training. The checkpoint threshold is trained on MVTec AD images. Real-world cameras produce different score distributions. The
/calibrateendpoint — upload N normal images, computemean + k*std— is the minimum viable solution for bridging that gap without retraining. -
Dependency conflicts are the real engineering cost. PatchCore training took 211 seconds. Resolving numpy 2.x, ollama SDK, and matplotlib API conflicts took longer. Pinning versions is the fix, but finding the right pins requires reading error traces, not documentation.
13. Conclusion
DefectVision demonstrates that unsupervised anomaly detection is production-viable for manufacturing inspection — with caveats. PatchCore delivers perfect benchmark scores on controlled datasets, but the 8–20pp drop on MVTec AD 2 shows that real-world deployment requires matching training data to deployment conditions, not tuning model hyperparameters. The most important design decisions were not about the model: they were about runtime calibration, non-blocking inference, and graceful degradation when the API is unreachable. These are the things that determine whether a CV system runs for 5 minutes in a demo or 5 months on a factory floor.